|
1
|
|
|
2
|
- Grundidee
- Modell schätzen
- Kontraste berechnen
- FFX vs. RFX
- Bunte Bilder in SPM2
- Nicht: Bayes, PPI (hrf deconvolution), DCM
|
|
3
|
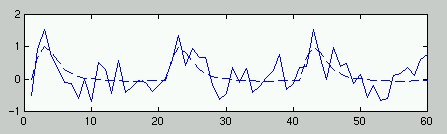
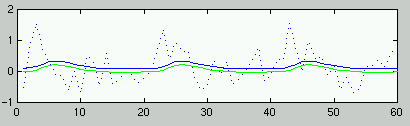
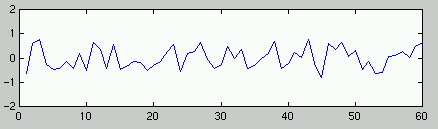
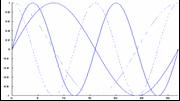
- voxel (=3d pixel) – basierte Statistik
- AV: Zeitreihe der Aktivationswerte pro Voxel
- UV: Modellzeitreihen der Prädiktoren (Experimentelle Bedingungen &
Confounds)
- Test = Korrelation zw. Meß- und Modellzeitreihe <> 0?
|
|
4
|
|
|
5
|
|
|
6
|
|
|
7
|
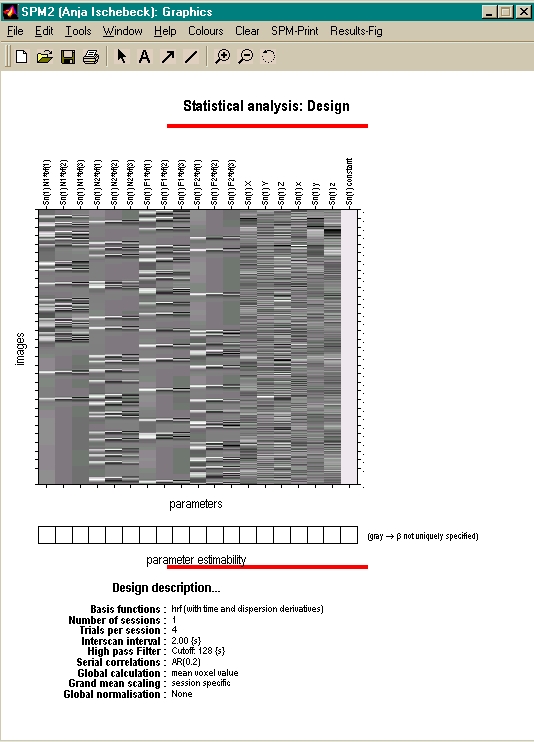
- Formel: b = (Xτ X)-1 Xτ Y
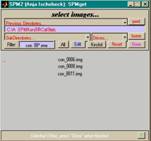
- input:
- data nach Prepro: swar*.img/.hdr
- design matrix: X
- Output: beta_0001.img/.hdr
- Prädiktoren:
- Exp. Bedingungen
- Moco Params
- Filterfunktionen
- Soviele Bilder wie Prädiktoren
|
|
8
|
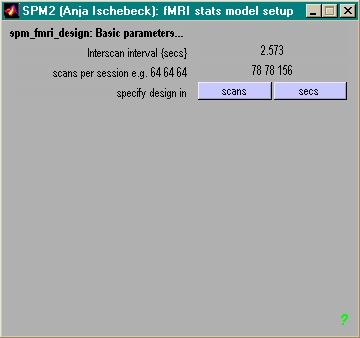
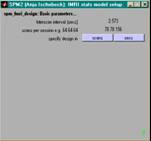
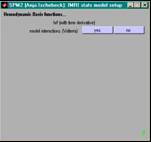
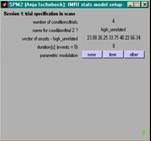
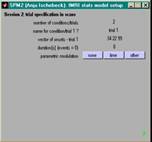
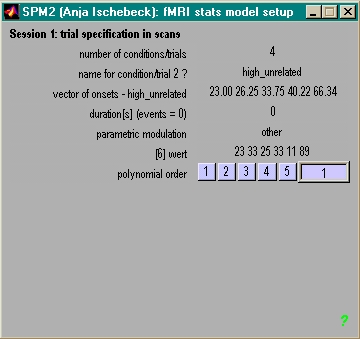
- Angaben (pro VP & Session) machen
- nur einmal
- Anzahl scans, TR in secs (mit Dezimalstellen)
- pro Session
- Anzahl und Namen der exp. Bedingungen
- Onsets der Trials pro Bed. (in secs oder scans)
- duration of trials in secs (0 für event-related)
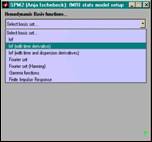
- Modellierung
- events oder epochs
- Art der hrf-Modellierung
- zusätzliche Covariate (z.B. moco)
- weitere optionen (Volterra, AR(1), HP Filter, global scaling)
|
|
9
|
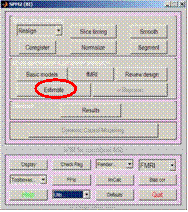
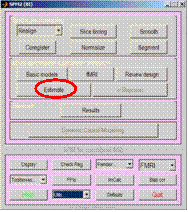
- Modell Spezifizieren
- Modell Schätzen (= rechnen lassen)
|
|
10
|
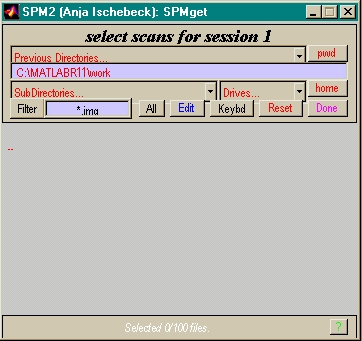
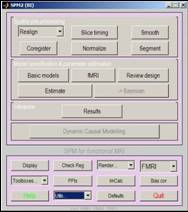
- Hier: Menü (realistischer über Skript)
|
|
11
|
|
|
12
|
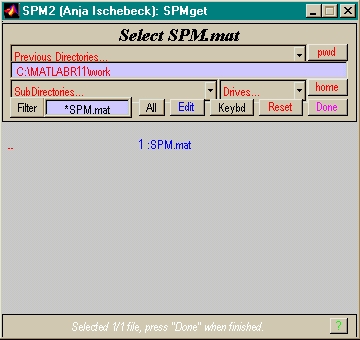
- ergänzt SPM-mat
- um Daten (func Bilder)
- weitere Modellparameter
|
|
13
|
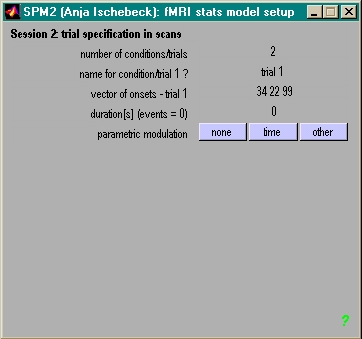
- Block: z.B. Duration = 30
- Spez. als Blockdesign Vorteil:
- weniger onsets, weniger Arbeit
- Spez. als Blockdesign Nachteil:
- besser wenn als einzelne Events modelliert
- Fehler können aus der Analyse raus
- statistisch sensitiver als Blockanalyse!
|
|
14
|
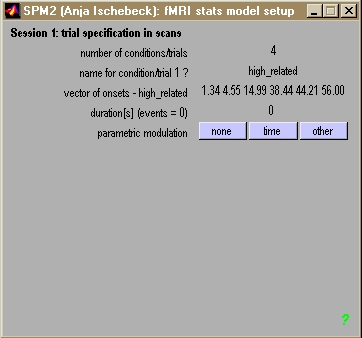
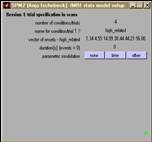
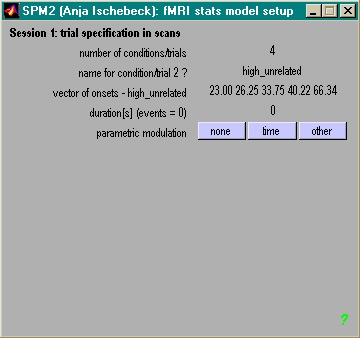
- Einmal pro Modellschätzung
- Einmal pro Session
- Anzahl der Bedingungen, Anzahl der Scans
- Einmal pro Bedingung
- Onsets
- Anzahl / Art der Parameter
- Duration (0=event-related, x=Blockdesign)
|
|
15
|
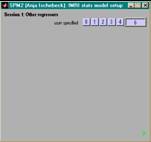
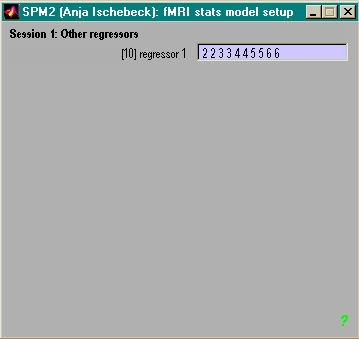
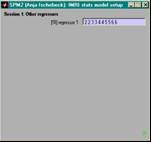
- ein Wert pro Trial & Bedingung
(z.B. RT, Wortfreq.)
- 'other' wählen
- soviele Werte wie
onsets eingeben
- order: 1=linear
- Achtung!
- ergibt zusätzliche
Prädiktoren!
(2 pro Bed. falls hrf')
|
|
16
|
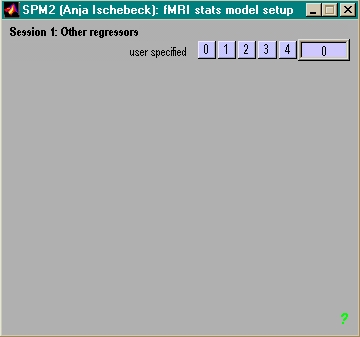
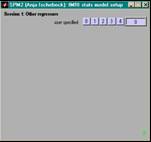
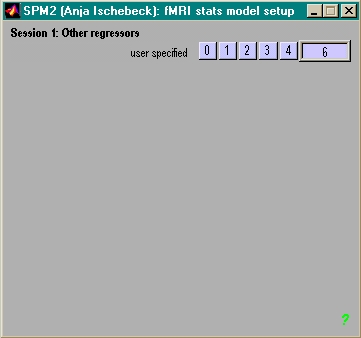
- ein Wert pro scan (z.B. moco-params)
|
|
17
|
- Statistik
- Referenz Schicht (slice time correction) = mittlere Schicht (default)
- Aber Referenz Schicht für Statistik = 1!
(default) à Ändern
(sampled bin = 8)
- Wieso diese Diskrepanz ?
- Effekt (auf Z-Werte) meist eher zum schlechteren
- (Erbsenzähler vs. crazy scientist)
|
|
18
|
|
|
19
|
- Output:
- beta_00x.img/.hdr
- Resl_00x.img/.hdr
- ResMS.img/.hdr
- mask.img/.hdr
|
|
20
|
- Spezifizieren ist aufwendig
- ein Fehler => alles von vorn!
- batch-file schreiben (Skript)
- onsets in Text-file oder direkt in Skript schreiben
- cond1 = [1.2 3.45 6.0 15.33 ...];
- cond2 = [2.5 7.5 12.0 20.34 ...];
- .....
- Rest über Menü
|
|
21
|
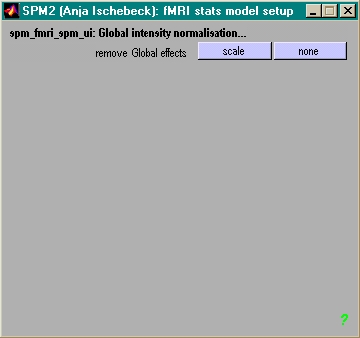
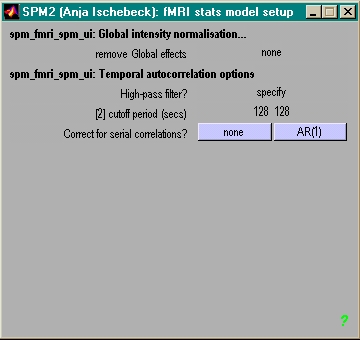
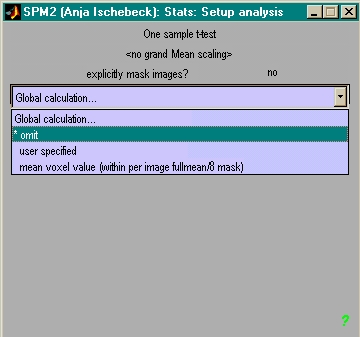
- Global Scaling ('none')
- globale Intensität pro voxel korrigieren
- besser nicht tun, führt zu Artefakten!
- in SPM integriert: global für gesamtes Bild
- HP-Filter (in sec)
- Wichtig! Optimum suchen bei einer VP!
- gar kein Filter so desatrös wie zu scharfer Filter!
- Faustregel: 2 mal max. Abstand zwischen 2 Trials einer Bedingung
- Idealwert hängt ab vom Kontrast! (Baseline vs. between Cond.)
- Wichtig: Ein Wert für gesamte Anaylse!
|
|
22
|
- AR(1)
- 'whitening', korrigiert für nicht i.i.d. errors
- etwas konservativ (SPM99: sehr konservativ)
- am besten ohne (crazy sientist vs. Erbsenzähler)
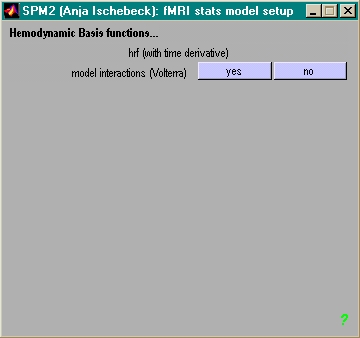
- Volterra
- Resultate REALLY scary (nur verlangt für ISI < 2s)
- moco als Regressor
- verbessert meist die Sensitivität der Statistik
- Anzahl der Bedingungen
- zuviele: schlecht! (kleines df)
- zuwenige: schlecht! (unaufgeklärte Varianz)
|
|
23
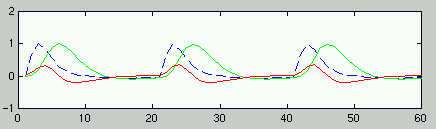
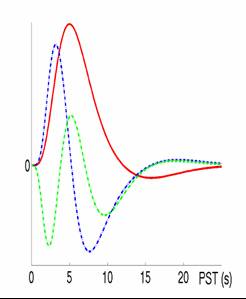
|
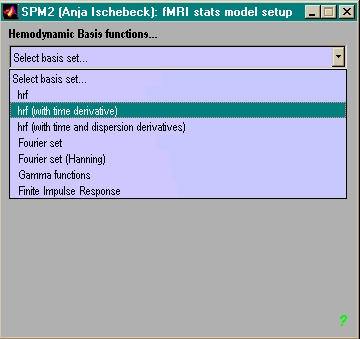
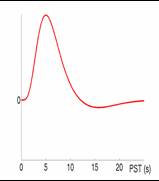
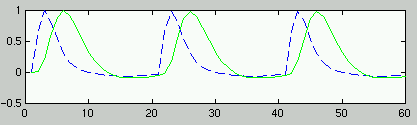
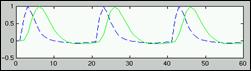
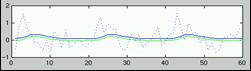
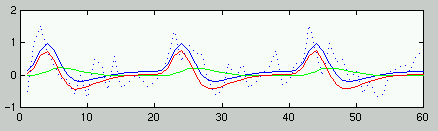
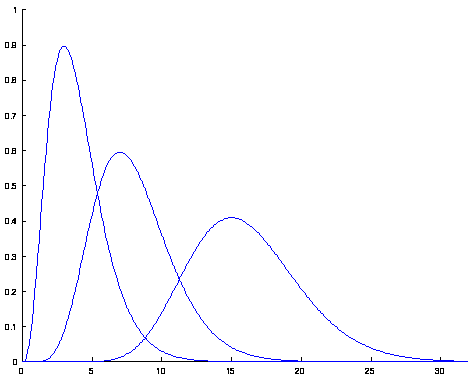
- Modell der BOLD Response für
ER-Design:
Summe von 2 Gamma-Funktionen mit festen Parametern (Peak at 6 s):
'canonical hrf'
|
|
24
|
|
|
25
|
|
|
26
|
|
|
27
|
|
|
28
|
- am effektivsten (weitaus 'beste' Statistik)
- hrf (evtl. mit hrf', hrf'')
- also andere nur in Spezialfällen
- sparse sampling
- evtl. bei sehr kurzem ISI
- Caveat:
- IBS: Timing ist kritisch!
- Maxima liegen etwas anders bei anderen Werten (z.B. peak bei 4s, 5s,
6s)!
- Gilt auch für verschiedene Arten slice timing
- Wichtig für Datenverständnis / Interpretation!
|
|
29
|
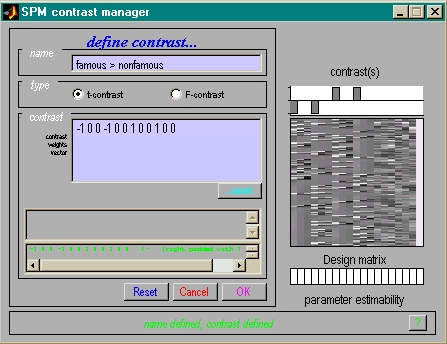
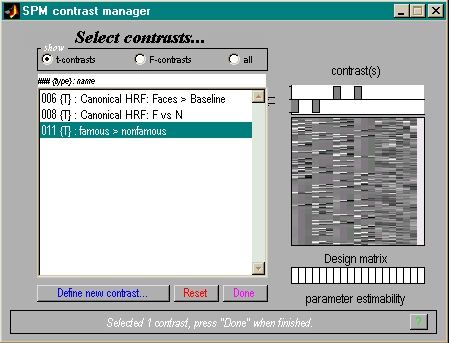
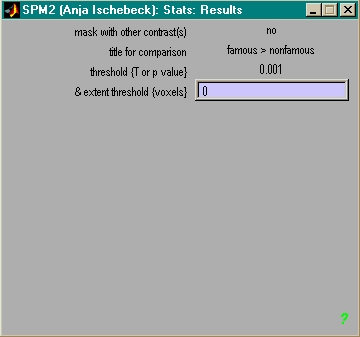
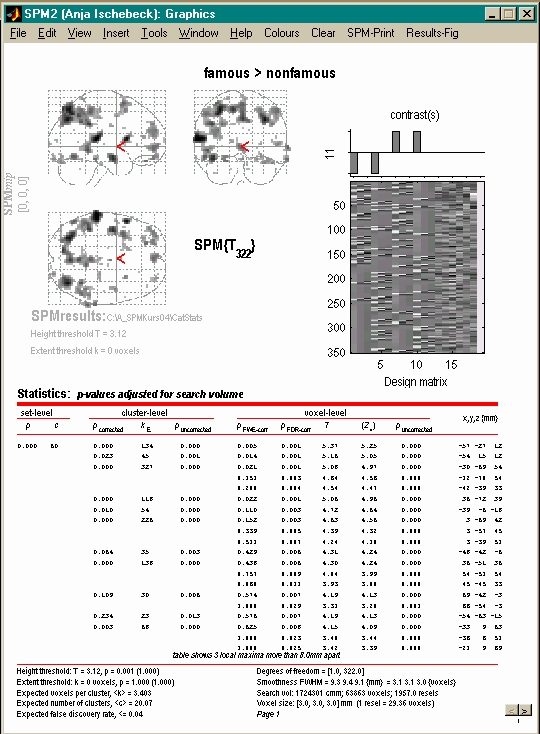
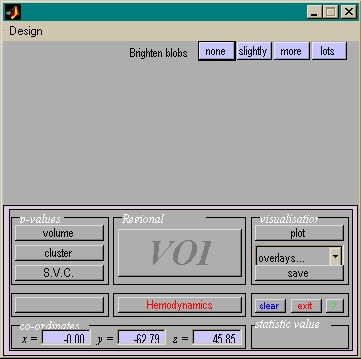
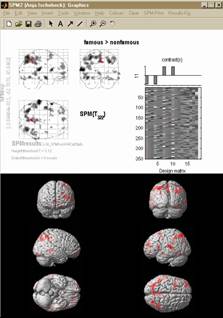
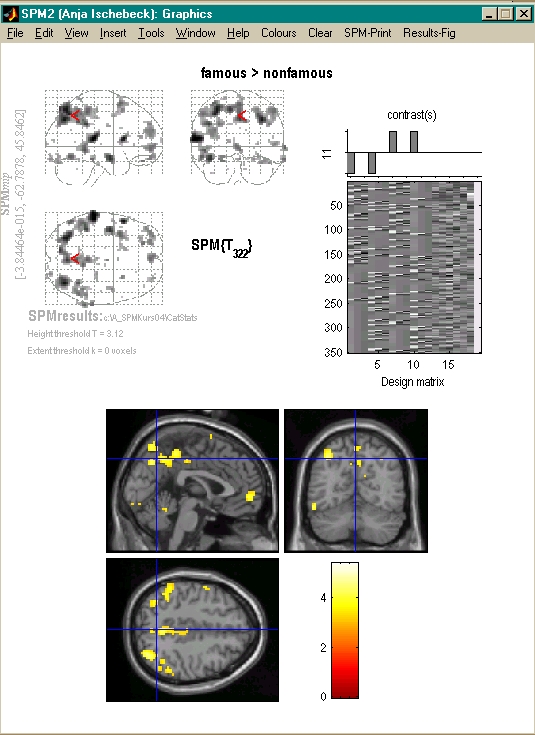
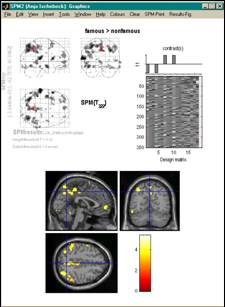
- Kontrastvektor schreiben
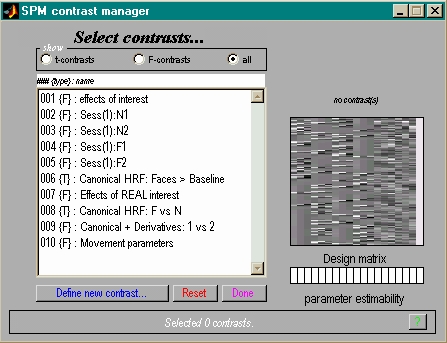
- Konstrast auswählen
- Schwelle festlegen
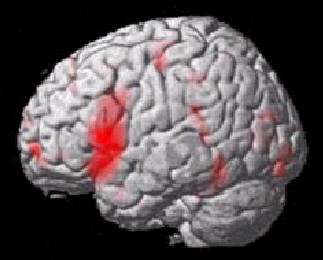
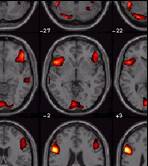
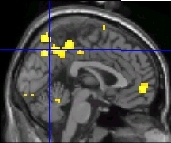
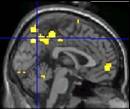
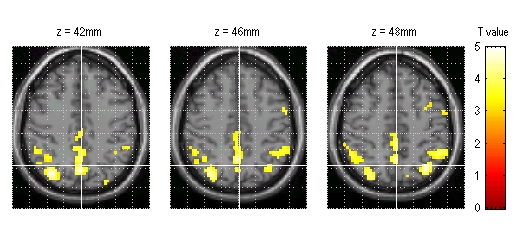
- Resultate ansehen
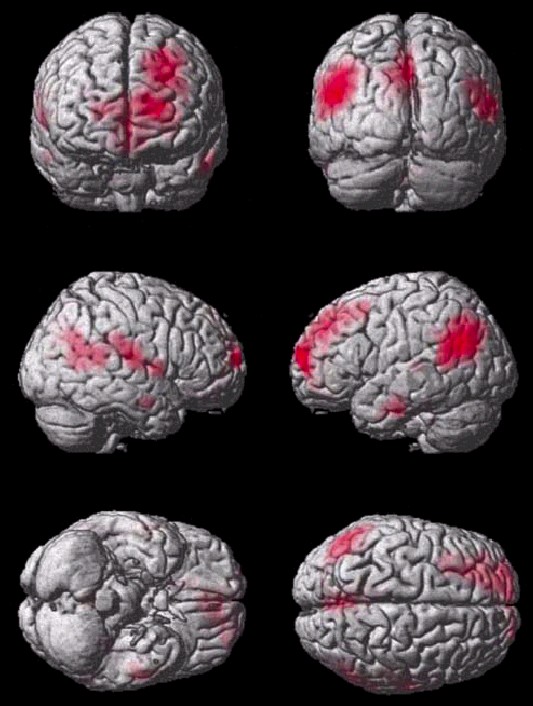
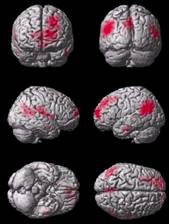
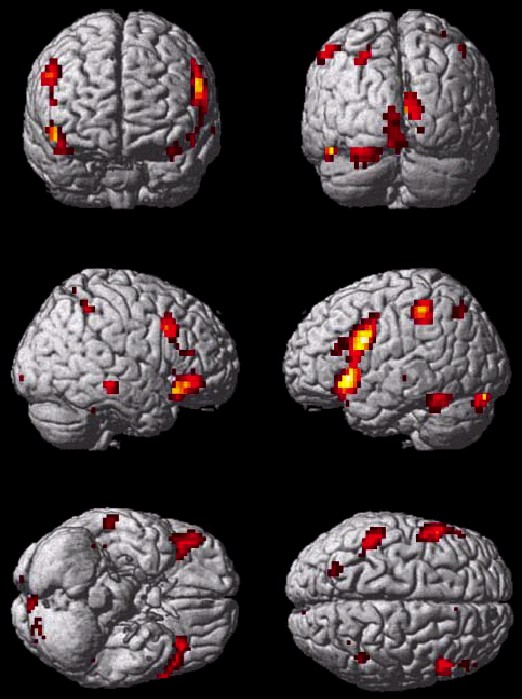
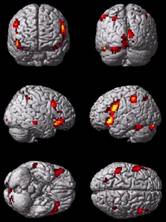
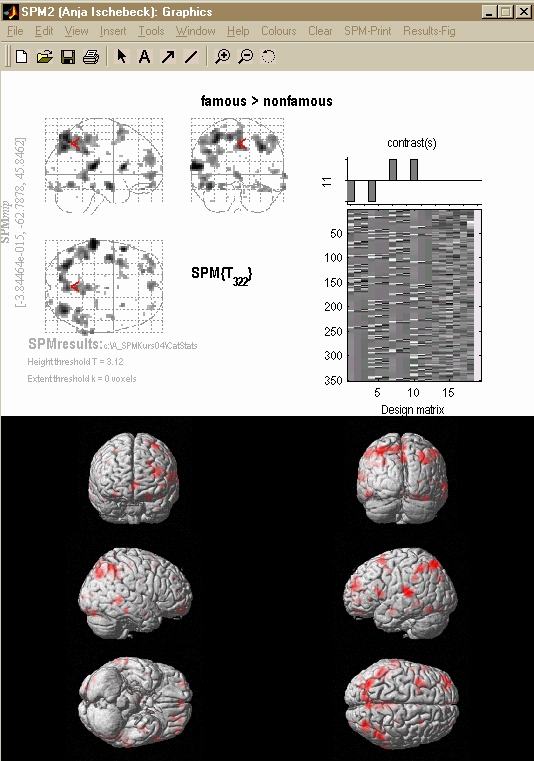
- Bunte Bildchen
|
|
30
|
- für gültigen t-Kontrast (Summe = 0)
- falls hrf: 1 Prädiktor, '1' pro Bedingung
mit hrf': '1 0'; mit hrf'': '1 0 0'
- fehlende Nullen am Ende werden automatisch ergänzt
|
|
31
|
|
|
32
|
|
|
33
|
|
|
34
|
- T&T=Atlas von Talairach & Tournoux (Stereotaxic Atlas of the
Human Brain, Talairach and Tournoux, 1988)
- MNI Gehirn weicht von T&T Atlas ab!
- Konvertierung:
- (http://www.mrc-cbu.cam.ac.uk/Imaging/mnispace)
- für z<0: xTT = 0.99x; yTT = 0.9688y + 0.042z;
- zTT = -0.0485y + 0.839z
- für z>0: xTT = 0.99x; yTT = 0.9688y + 0.046z;
- zTT = -0.0485y + 0.9189z
|
|
35
|
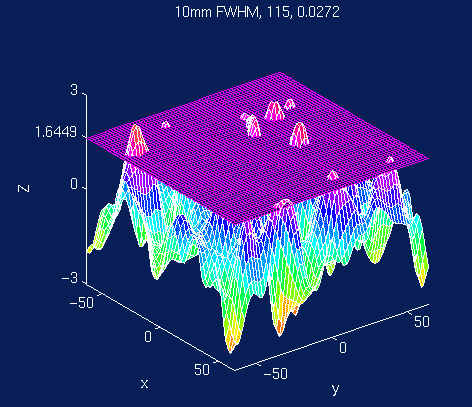
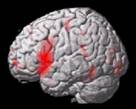
- multiple comparison problem (ca. 20.000 voxel insgesamt)
- Bonferroni ist zu konservativ (Tests sind nicht unabhängig)
- Random fields Theorie:
- Gegeben eine Erstschwelle,
- wieviele 'Blobs' überleben rein zufällig (=Euler characteristic) bei
einer gegebenen Körnigkeit (smoothness) des Bildes (Resels = unabhängige
Einheiten)?
- wenn mehr: signifikant
|
|
36
|
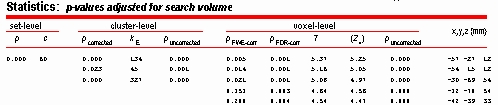
- verschiedene levels
- voxel level: wieviele cluster?
- cluster level: berücksichtigt Größe
- set level: berücksichtigt ganzes Ensemble
- Achtung:
- voxel level p–Wert manchmal konservativer als Bonferroni! => SPM
verwendet dann (klammheimlich) den weniger konservativen
Bonferroni-Wert
|
|
37
|
- will Fehler der ersten Art minimieren
- berücksichtigt nicht die clustergröße
- hat einen Bias (the rich get richer)
- falls irgendwo eine starke Aktivierung ist (e.g. visueller Kortex),
wird die Schwelle stark erniedrigt (evtl. zu Unrecht)
- bei insgesamt wenig Aktivierungen: fast konservativer als FWE
|
|
38
|
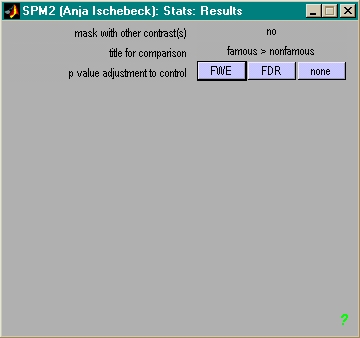
- Wenn Daten gut:
- Erstschwelle: p (FWE) < 0.05
- Berichten: pcorr(FWE) < 0.05 on clusterlevel
- Wenn Daten weniger gut:
- Erstschwelle: puncorr < 0.001 ('none')
- Berichten: pcorr < 0.05 on clusterlevel
- Wenn Daten ganz schlecht:
- Erstschwelle: puncorr < 0.005 ('none')
- Berichten: pcorr < 0.05 on clusterlevel
- Wenn Daten grottenschlecht:
|
|
39
|
- 2x2 Design = a1 b1 a2 b2
- Haupteffekte:
- a>b = [1 -1 1 -1]; b>a =
[-1 1 -1 1]
- 1>2 = [1 1 -1 -1]; 2>1 =
[-1 -1 1 1];
- Interaktion:
|
|
40
|
- F vs. t
- t-Kontrast: Vektor mit Zeilensumme 0
- F-Kontrast: Matrix
- 2x2 Design (a1 b1 a2 b2)
- Haupteffekte (zweiseitiger Test):
- F (ab) = [1 -1 1 -1;-1 1 -1 1]
- F (12) = [1 1 -1 -1;-1 -1 1 1]
- Interaktion:
- F (I)= [1 -1 -1 1; -1 1 1 -1]
- uninteressante Prädiktoren: 0
|
|
41
|
- Länge des Kontrastvektors (pro Block!):
- z.B. 6 Bedingungen (hrf & hrf') = 12
- mit 6 moco params = 18
- mit 1 Blockmittelwert = 19
- Exakte Länge für Skripting wichtig!
- Prädiktoren werden für jede Session/Run neu geschätzt
- Verlust an df!
- Grund: Funktionelle Runs sind sehr unterschiedlich (offset, Varianz,
scanner drift) Ausreißer stören die Analyse sehr!
- Am Besten: Alles in einem Rutsch /Scan
|
|
42
|
- Also warum t-Tests und nicht F-Tests?
- hätte man gerne, wenn es ginge
- Geht: FFX; Geht (noch) nicht: RFX
- Am besten: Einfache 2x2 Designs!
- 2x3 Design bereits schwer zu rechnen (viele t-tests, statt F-test mit
HE/I)
- Interpretation nicht immer leicht
- Platz im Artikel begrenzt
|
|
43
|
- soviele wie Prädiktoren:
- soviele wie Kontraste:
- con_00x.img/.hdr
- SpmT_00x.img/.hdr bzw. SpmF_00x.img/.hdr
|
|
44
|
- FFX = Bisherige Analyse:
- FFX = fixed effects model
- Analyse einer VP mit mehreren Sessions/Runs
- falls mehrere VPs: Analyse als eine VP mit mehreren Sessions!
- eine extreme VP kann das Ergebnis dominieren!
- RFX = Analyse über mehrere VPs
- RFX = random effects model
- wird nach FFX über die con-images der einzelnen VPs gerechnet (2nd
level analyse)
- erlaubt Verallgemeinern auf Population
|
|
45
|
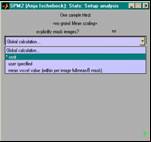
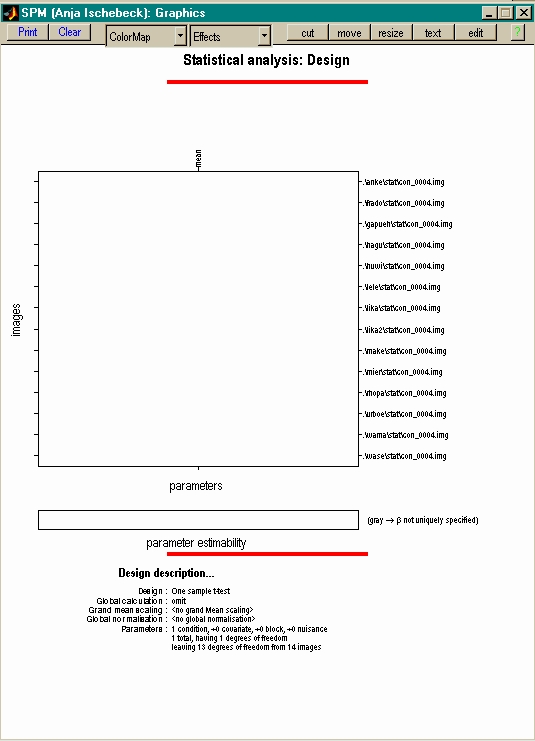
- 2 Schritte:
- 1. Schritt FFX:
- Modell schätzen für einzelne VPs
- Kontraste rechnen lassen
- 2. Schritt RFX
- one-sample t-test rechnen über con_images
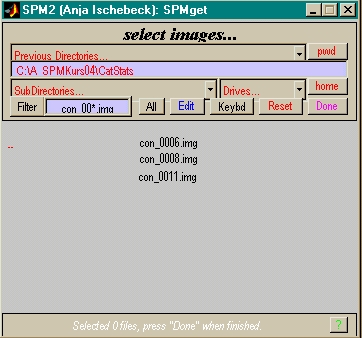
- Pro Kontrast und VP ein Bild
- bis 10 VPs zu konservativ
|
|
46
|
- Sensitivität:
- unter 10 VPs: Fixed Effects Analyse (FFX)
- über 10 VPs: Random effects Analyse (RFX)
- FFX: Eine VP kann Resultat dominieren
- RFX: erlaubt das Verallgemeinern auf die Population
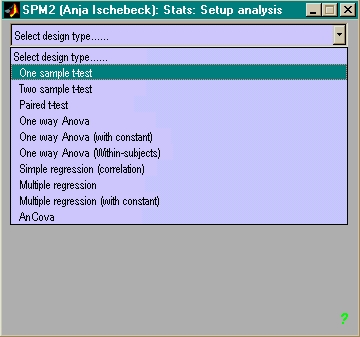
- RFX-Analyse - Prinzip:
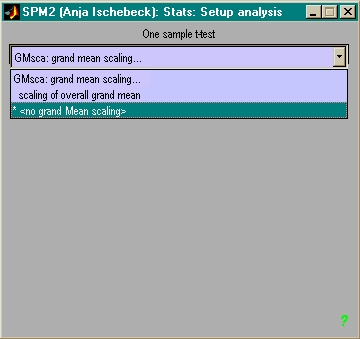
- 1 Gruppe VPs: über Bilder eines Kontrastes one-sample t-test rechnen
- 2 Gruppen (Pat. & Kontr.): über Bilder eines Kontrastes two-sample
t-test rechnen
- Neu (SPM2): RFX auch mit F-Kontrasten!
|
|
47
|
|
|
48
|
|
|
49
|
- Model schätzen lassen (SPM fragt)
- Kontrast definieren:
- one-sample t-test: 1
- two-sample t-test: 1 –1
- Schwelle angeben
- Resultate ansehen
|
|
50
|
- pro VP ein Wert (z.B. IQ, Fehlerrate)
|
|
51
|
- Caveat 1:
- SPM.mat nicht portabel
- Pfade zu den Dateien fix kodiert
- Volumes Toolbox schafft Abhilfe
- Caveat 2:
- Vorsicht bei der Def. von Kontrasten
- Man kriegt sie nur schwer wieder aus SPM.mat raus
- Caveat 3:
- Ausreisser (> 3 SD): Anfangsscans, zerstörte Scans
- altes Tool von Russ Poldrack (SPM99): global_plot.m
- für SPM2: ai_global_plot.m von mir
|
|
52
|
|
|
53
|
|
|
54
|
|
|
55
|
|
|
56
|
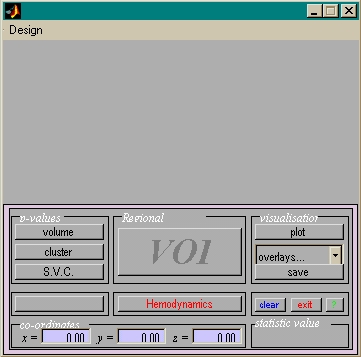
- geht nur im Resultate-Menü:
- Resultate, Kontrast auswählen, Schwelle setzen
|
|
57
|
|
|
58
|
- abhängig von Position des Cursors
- Werte / Schnittebene fix
- besser: display_slices.m (nur für SPM99)
|
|
59
|
- Generell:
- Umständlich über den Kontrastmanager
- dauert lange bei großem SPM.mat
- Ausdrucken:
- screenshot (Qualität soso)
- besser: Print option => spm.ps
- Andere Tools:
- Templates zum Visualisieren:
- alle normalisierten (Anat)-Bilder (unterschiedliche Auflösung)
|
|
60
|
|

 Notizen
Notizen{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
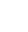{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}